Real-time analysis of neural data
A software platform (improv) for designing and orchestrating adaptive experiments — analyzing neural data in real time to measure, model, and manipulate brain activity, with Eva Naumann’s lab.
Read moreRead less
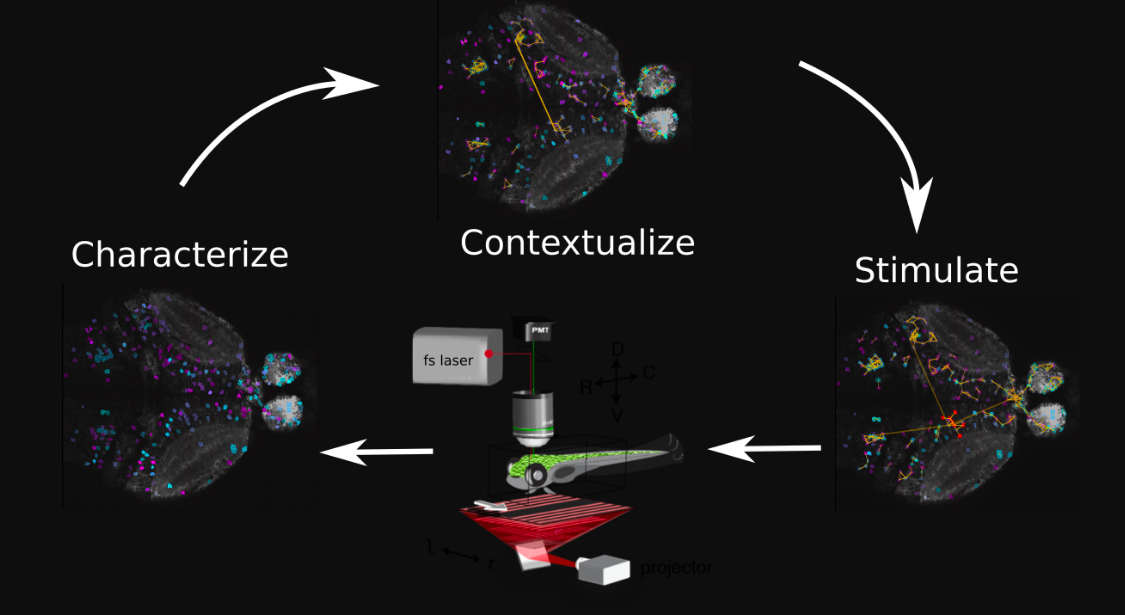
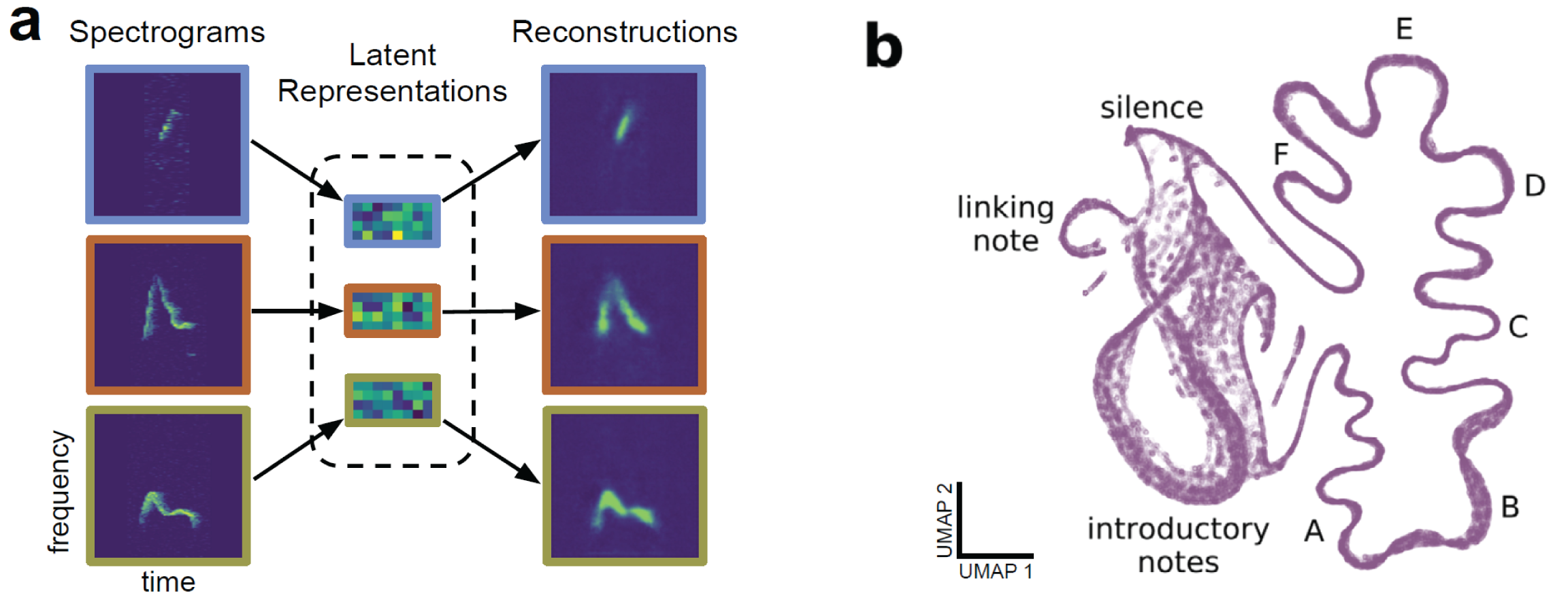
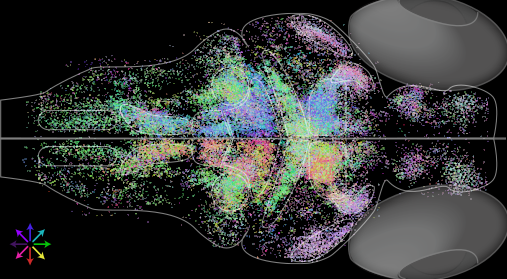
Together with Eva Naumann’s lab, we’ve developed improv (paper), a software platform for designing and orchestrating adaptive experiments. By analyzing data in real time, we can measure, model, and manipulate neural activity in response to new data. We’ve shown how these tools, in conjunction with holographic photostimulation, could in principle map functional connectivity of large circuits in a few hours (paper, expanded version). More recently, we’ve worked on methods for fast dimensionality reduction and modeling of neural populations in real time (paper).